
Five plans for navigating the intelligence explosion
A stab at thinking through the main AI governance plans and their necessary conditions.

Roughly twice a year I stress out about the plan for developing and deploying powerful AI systems in a somewhat responsible manner. Sometimes my calls are then side-tracked with rants about how all the options seem undesirable/unworkable/”deeply icky”/etc. Overall, I think I endorse this orientation. I suspect more people should have a picture of what they want society to actually aim for in the near future to navigate an intelligence explosion well.1
So what might a good plan look like? There are a few criteria that jump to mind:2
Develop powerful AI systems safely and securely. They should not be catastrophically misaligned or create opportunities for users to take catastrophic actions.
Maintain a low level of geopolitical instability throughout the intelligence explosion. There shouldn’t be a nuclear war, or states coming close to seizing power.
Make sure that extremely high-stakes and irreversible actions are carefully considered and humanity realises vast flourishing.
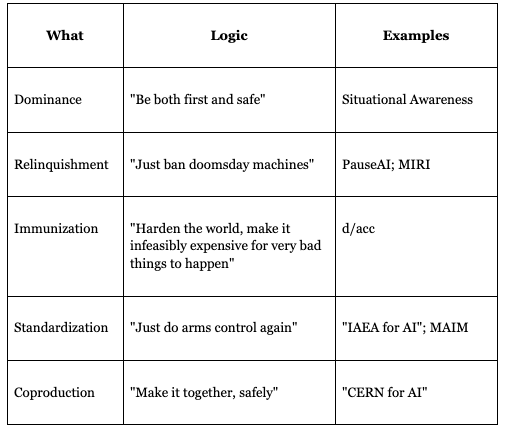
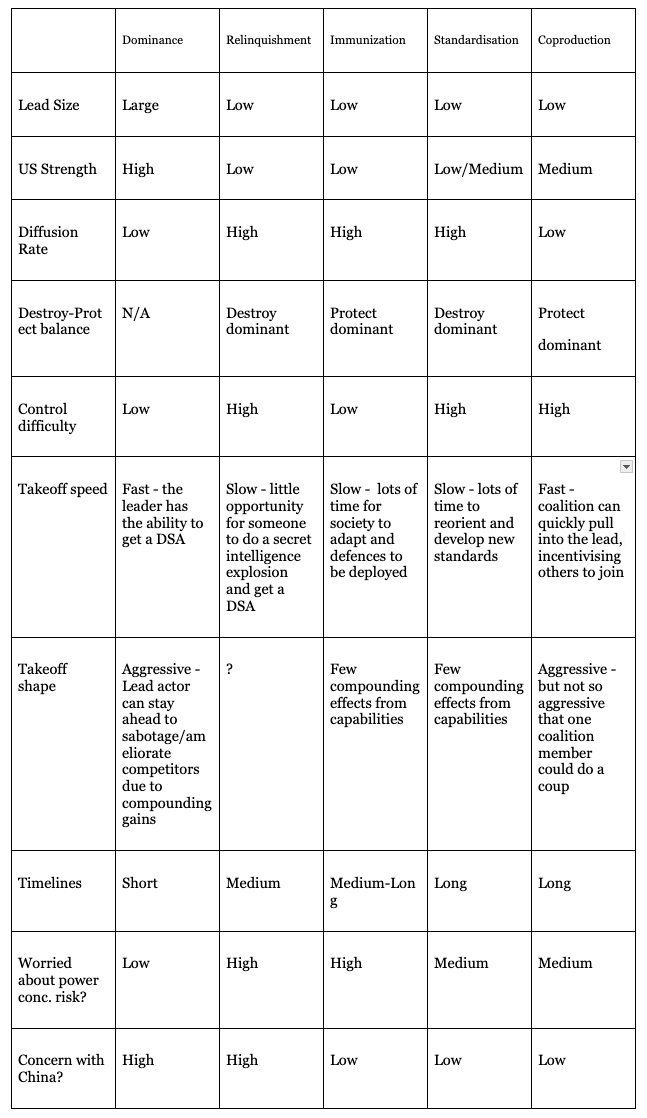
I think navigating an intelligence explosion in the next few years, with the natural evolution of the current political climate, training setup, and AI companies will be pretty rough. I refer to the current plans as dominance, relinquishment, immunization, standardization, and co-production. Here are some vignettes to help illustrate why, with some thoughts on what I’d need to see to make me think the part was a good one.3
Dominance
Think situational awareness.
The United States, through either its government agencies or a leading private tech company, achieved a decisive technological breakthrough in artificial intelligence development (e.g. end-to-end automation of AI R&D). This creates a substantial lead over international competitors, providing a critical window to address safety concerns while maintaining technological superiority. The US invests heavily in alignment research, ensuring their systems remain robustly controlled and aligned with human values. Rather than keeping all benefits to themselves, they established a careful program of sharing limited capabilities with trusted allies through tightly monitored partnerships. For nations outside this circle, they created a dual system of incentives and deterrence, offering economic benefits for cooperation while maintaining credible military and economic threats against those pursuing potentially dangerous AI development paths. Through targeted sanctions, diplomatic pressure, and occasional demonstrations of their technological edge, they effectively discouraged dangerous arms races. This stable monopoly allowed for the careful governance of global AI development, preventing catastrophic risks while gradually allowing beneficial applications to spread under strict supervision, creating a Pax Americana of artificial intelligence.
When could dominance work?
The dominant power’s lead size needs to be large or AI control needs to be easy, so that they have enough time to make sure that AI systems are safe before they are deployed.
Alternatively, takeoff speed could be aggressive such that a small initial lead quickly results in the developer having a large strategic advantage. This could either happen because:
There are large AI R&D algorithmic or compute returns to marginally more powerful AI systems (models can run experiments more quickly or come up with better hypotheses to test).
AI labs with better models are more able to raise capital, meaning they can buy more compute, hire more people etc.
The diffusion rate of algorithmic secrets needs to be low so that reckless actors don’t deploy their own powerful AI systems. This could come from security being easy with powerful AI systems, compute requirements making deployment restrictive (lots of compute required or very specialised compute required), or verification of other countries data centre use (potentially with AI assistance).
The dominant power needs to eventually share the benefits of powerful AI with other countries, either via trade or altruism.4
The strategy makes most sense if you have either:
A high degree of confidence in the dominant power acting significantly more benevolently than other actors.
Or you are very worried about diffusion of power risks where many people have access to powerful AI systems because you either:
Can’t get strong assurances that AI users will only use their AI systems benevolently.
Can’t get strong assurances that AI systems will act benevolently in cases where their users want them to take harmful actions.
Relinquishment
As computing capabilities accelerated, leading AI developers and major governments recognized an uncomfortable truth: safety techniques were significantly lagging behind capability development. After a series of near-miss incidents with increasingly powerful systems, key stakeholders agreed to a temporary but comprehensive moratorium on developing AI beyond certain capability thresholds. This wasn’t a permanent abandonment of advanced AI, but rather a strategic pause. During this period, unprecedented resources flowed into fundamental AI safety research, while international verification systems were established to detect violations of development limits. The moratorium wasn’t without tension—economic pressures and national security concerns created constant temptation to defect from the agreement. However, clear criteria for what constituted “sufficiently safe” AI development provided a roadmap for progress. After several years of intensive safety research, breakthroughs in interpretability and alignment allowed for a carefully phased resumption of development. When truly advanced systems were eventually deployed, they came with robust safeguards against catastrophic risks, having been developed under a cooperative framework that prioritized safety over speed.
When could relinquishment work?
Most risk comes from deploying misaligned or misusable systems as opposed to marginal latent risk (e.g. from bioweapons).
AI control is very hard, and progress is not particularly bottlenecked on AI capabilities.
The coordination cost is viable, either because one actor is far ahead, or because multiple actors can make strong commitments to each other to pause. It’s hard for some actors to defect and secretly develop AI despite increasingly inexpensive compute.
There are clear triggers for a pause, like a significant warning shot or consensus on unacceptable risk thresholds and ways of measuring risk. This seems more likely to happen if:
Takeoff is slow enough that society has time to orient to AI progress and its effects, and a catastrophe doesn’t happen before there is time to enact a pause.
But, fast enough such that we don’t get “frog-boiled”.
There are avenues to exit the pause and build safe and powerful AI systems in a non-geopolitically destabilising manner with significant distribution of benefits.
Immunization
Think d/acc.
Rather than attempting to prevent advanced AI development, governments and companies focused on making society resilient against potential harms. They recognized that perfect control was impossible in a world of distributed computing and multiple competitive actors. Instead, they pursued a strategy of comprehensive defense-in-depth. AI systems were developed specifically to detect and counter potential AI-enabled threats, from cyberattacks to biological hazards. Critical infrastructure received massive upgrades to withstand sophisticated disruption attempts, while early warning systems for pandemic threats incorporated AI analysis to identify dangerous pathogens before they could spread widely. Public education campaigns helped citizens understand AI capabilities and limitations, reducing vulnerability to manipulation. When bad actors occasionally deployed harmful AI applications, these layered defenses successfully contained the damage. Each incident led to further refinement of protective measures. By the time AI capabilities had advanced dramatically, society had developed sufficient resilience that catastrophic misuse remained theoretically possible but practically unfeasible, with multiple independent safeguards ready to neutralize threats before they could cascade into truly global catastrophes.
When might immunization work?
Lots of risk comes from power concentration.
Ultimately, defences advance more quickly than attacks either because AI turns out to be more useful for creating defences or because defensive actors have more resources to spend on AI than offensive actors.
This plan is more favourable with high diffusion rates of AI (or AI enabled goods) so that benefits and defences can be spread more quickly and risks from power concentration are reduced.
Timelines need to be relatively long, but more importantly, takeoff needs to be shallow enough that society has plenty of time to build defences that keep pace with increasingly powerful AI.
Standardization
Think IAEA for AI, parts of MAIM.
As multiple nations approached the threshold of developing transformative AI systems, the specter of a dangerous and destabilizing arms race loomed large. In response, major powers established a robust international framework for AI development with verifiable standards and meaningful enforcement mechanisms. An independent international body with substantial technical expertise was formed to oversee compliance, conducting regular physical inspections of computing facilities and monitoring training runs. Technical standards balanced innovation with safety, requiring transparency in development processes without exposing sensitive IP. When a mid-sized power was caught attempting to circumvent these standards, swift and coordinated sanctions demonstrated the collective will to enforce the agreement. Over time, the standardization regime created a stable international order where multiple countries could pursue AI development along parallel tracks, but within guardrails that prevented unilateral actions that might prove destabilizing. The technical measures developed to detect and attribute violations became increasingly sophisticated, making non-compliance progressively more challenging to conceal. By distributing both the benefits and responsibilities of advanced AI development, the standardization approach successfully navigated the complex geopolitical landscape while minimizing existential risks.
When might standardization work?
Most risk comes from misalignment, and misuse. Security is relatively easy despite the significant security costs of verification.
There exist enforcement mechanisms that aren’t immediately invalidated if one country has an unexpected AI capabilities jump.
There is political appetite to enforce the treaty.
No single uncooperative nation has a large lead, and timelines are long enough and shallow enough to build significant institutions and infrastructure.
There are multiple parties that could plausibly train powerful AI systems soon and diffusion rates are high enough that it’s inevitable that other actors will eventually get powerful AI systems (e.g. by stealing the models).
Coproduction
Think Intelsat or CERN for AI.
Recognizing both the potential benefits and dangers of advanced AI systems, several major economic powers chose a path of deep collaboration rather than competition. They established a joint venture to develop frontier AI capabilities, pooling their resources to build computing infrastructure far beyond what any single nation could achieve independently. The partnership included distributed research teams across participating countries, with transparent governance structures giving all partners meaningful input into development decisions. Each nation maintained visibility into the project through their own security protocols, alleviating fears that the technology might be weaponized against them. When the breakthrough to significantly more capable systems came, the shared ownership model ensured that no single actor could monopolize the capabilities or rush deployment without consensus. The cultural and linguistic diversity incorporated into the system’s design prevented bias toward any particular nation’s interests. Economic benefits flowed to all participating countries according to pre-established agreements, creating a positive-sum outcome that reinforced the value of cooperation. By transforming what might have been a dangerous race into a collaborative endeavor, the coproduction model successfully navigated the transition to advanced AI while maintaining geopolitical stability.
When might coproduction work?
Timelines are long enough such that there are only large gains from large investment (e.g. most progress comes from compute scaling) and there’s time to develop coalitions.
No uncooperative country has a large lead, such that it’s not incentivised to join the coalition and could gain significant power over the coalition.
If there is, it still might be worth forming a coalition to try and stay in the race.
AI progress is relatively fast and compounding, such that the coalition can stay well ahead of potential competitors, but not so fast that any one coalition member with model access gets a good opportunity to takeover the project.
Security is relatively easy, such that a large project with many stakeholders isn’t unfeasibly expensive to secure.
Is analysing plans useful?
It turns out that you can in fact just write things on the internet and sometimes people will change the direction of their work, join your project, or not start projects because of your takes. That alone, in my opinion, should incentivise more discussion of plans.
People talk about policymaking as making incremental improvements on the margin when good opportunities (i.e. policy windows) arise. This is reasonable, but it’s a much better strategy if there are many good and mutually compatible intermediate goals, and it’s not clear to me that there are. The usefulness of various policies often turns on the broader plan.
Whilst working out a single coherent plan for everyone trying to make AI go well to follow doesn’t sound like a very productive exercise, I’d like to see more people try to explain their actions in reference to specific plans, and explain why those specific plans are actually relevant (e.g. in touch with the expected political climate, training and deployment regime, distribution of compute …) good - in the sense that they’ll move society to a place where AI will enably vast flourishing and won’t cause a catastrophe.
There are two public efforts (that I know of) that are trying to publicly communicate a coherent vision for an AI governance regime that thinks through lots of steps in the game tree - h/t to MIRI, and the AI Futures Project.
I’m sure there are other criteria as well, this list isn’t particularly thoughtfully considered.
I don’t want to paint a false polytomy, I know that you can pursue multiple paths at the same time, and you might want to do some in combination with others but I still think the naive single plan analysis is a useful exercise for thinking through the implications and viable conditions for an AI go well plan. E.g. coproduction within a dominant coalition or relinquishment as a temporary bridge to standardization).
Note that you may not need much altruism to enable mass flourishing, as powerful AI will likely make many expensive things cheap (e.g. economic security, food, yachts, a cure to aging, psychedelics as safe as coffee).
This was great! I find this to be quite a clean, nature-carving split. The main dimension I focus more on in my version of this (non-pubic as of yet) is how large a role companies versus governments play in AI development, which to me seems like a strategically relevant variable. But if we are picking only five categories, these do indeed seem like good ones to pick. I would be interested in someone doing a rough survey of AI governance folks on which one/s they most prefer (we are considering doing something like this).